" "
CryptoCurrencies Chart
Based on Python Web Crawling
 |
| https://steemit-production-imageproxy-upload.s3.amazonaws.com/DQmZg11BWDzBffTTSUFvypcvZvXZCWepFdNZPWAFyXWWxpy |
요즘, 가상화폐가 뜨고 있다.
평소에 ‘사이트에서 데이터를 가지고 와서 내가 직접 활용할 수 있으면 좋겠다’고 생각했는데, 인프런(Inflearn)이라는 사이트에서 웹 크롤링을 주제로 한 강의를 발견하면서 생각을 실현할 수 있게 되었다.
이번에는 명령을 원하는 시간마다 수행해주는 Crontab을 이용해 1시간마다 웹 크롤링(with scrapy[python])을 수행한 후, 얻어온 데이터를 DB에 저장할 것이다.
또한 웹 페이지를 만들어, DB에 저장된 데이터들을 기반으로 Google Chart를 이용해 그래프를 표시하게 만들 것이다.
Summary
: Crontab( Crawling( python - scrapy, selenium ) ) -> DB -> PHP(page) - HTML[Chart]
1. Crawling data with python using scrapy and selenium
and Storing the data in DB(MYSQL)
가장 먼저, 크롤링(crawling)이란 데이터를 추출해내는 행위를 뜻한다고 한다.
크롤링을 진행하기 위해서 python을 설치하고, scrapy의 사용법을 배울 것이다.
웹 크롤링과 scrapy의 사용법에 대해서는 https://www.youtube.com/channel/UCCZum2rAfq3SjjUFshYDZww/videos 에서 배우는 것을 추천한다.
또한 가상화폐의 값은 Bithumb이라는 사이트에서 가져올 것인데, 실시간으로 시세가 변하기 때문에 동적 크롤링을 진행하기 위해서는 selenium이라는 라이브러리도 사용한다.
마지막으로, DB에 데이터를 넣어주기 위해, mysql.connector를 import해주고, 데이터를 DB에 INSERT하게 된다.
크롤링을 진행하기 위해서 python을 설치하고, scrapy의 사용법을 배울 것이다.
웹 크롤링과 scrapy의 사용법에 대해서는 https://www.youtube.com/channel/UCCZum2rAfq3SjjUFshYDZww/videos 에서 배우는 것을 추천한다.
또한 가상화폐의 값은 Bithumb이라는 사이트에서 가져올 것인데, 실시간으로 시세가 변하기 때문에 동적 크롤링을 진행하기 위해서는 selenium이라는 라이브러리도 사용한다.
마지막으로, DB에 데이터를 넣어주기 위해, mysql.connector를 import해주고, 데이터를 DB에 INSERT하게 된다.
Python은 기본으로!
Python의 기본 문법은 점프 투 파이썬(https://wikidocs.net/book/1)이라는 사이트에서 쉽게 배울 수 있다.
Scrapy – 웹 사이트에서 필요한 데이터를 추출하기 위한 오픈소스 프레임워크
하지만 마음대로 웹 사이트에서 데이터를 가져다가 영리적으로 사용하려고 하면 저작권 문제가 생길 수 있다고 한다.
웹사이트/robots.txt 를 들어가보면 사이트의 크롤링 정책을 알 수 있다고 한다.
User-agent: *
Allow: /
Allow: /
라고 적혀있는데, 말 그대로 / (루트 디렉터리) 를 Allow(허용) 한다는 것이기 때문에 크롤링 할 수 있는 것이다.
모두 허용
User-agent: *
Allow: /
User-agent: *
Allow: /
모두 차단
User-agent: *
Disallow: /
User-agent: *
Disallow: /
다양한 조합
User-agent: googlebot # googlebot 로봇만 적용
Disallow: /private/ # 이 디렉토리를 접근 차단한다.
User-agent: googlebot-news # googlebot-news 로봇만 적용
Disallow: / # 모든 디렉토리를 접근 차단한다.
User-agent: * # 모든 로봇 적용
Disallow: /something/ # 이 디렉토리를 접근 차단한다.
User-agent: googlebot # googlebot 로봇만 적용
Disallow: /private/ # 이 디렉토리를 접근 차단한다.
User-agent: googlebot-news # googlebot-news 로봇만 적용
Disallow: / # 모든 디렉토리를 접근 차단한다.
User-agent: * # 모든 로봇 적용
Disallow: /something/ # 이 디렉토리를 접근 차단한다.
먼저, 독립적인 개발환경을 만들어주는 virtualenv를 깐다.
# sudo pip install virtualenv virtualenvwrapper
다음으로는 환경 설정파일을 건드려준다.
vi ~/.bashrc
# export WORKON_HOME=$HOME/.virtualenvs // 추가
이제 virtualenvwrapper.sh를 컴파일해준다.
# source /usr/local/bin/virtualenvwrapper.sh
virtualenv 명령어 (참고: http://1cue.blogspot.kr/2015/11/blog-post.html)
{
가상 환경 생성 : mkvirtualenv env_name
특정 python 버전으로 가상환경 생성 : mkvirtualenv –python=python3.4 env_name
가상 환경 제거 : rmvirtualenv env_name
가상 환경 실행 : workon env_name
가상 환경 종료 : deactivate
}
}
이제 가상환경을 생성/실행해주고 Scrapy를 깐다.
# mkvirtualenv env_name
# workon env_name
# pip install scrapy
또 리눅스 환경이면, firefox를 실행해 동적인 데이터를 가져와서 활용하기 위해 selenium을 깔아준다.
# pip install selenium
또한 geckodriver도 깔아준고, PATH변수에 경로를 추가해준다.
이제 scrapy 프로젝트를 생성해준다
# scrapy startproject project_name
이제 scrapy에 대한 다양한 정보는 https://scrapy.org/ 에서 볼 수 있고,
이제 추출해 올 데이터 항목들을 담는 items.py 에다가
import scrapy class CrawlingItem(scrapy.Item): coinName = scrapy.Field() coinPrice = scrapy.Field() date = scrapy.Field() pass
라고 적어준다.
그러면, coinName, coinPrice, date가 얻을 정보(항목) 된다. (사실 date는 파이썬 내부에서 generated 될거지만, 화폐 시세를 표현하기 위한 중요한 정보이므로 포함한다.)
그리고 이제 메인이 되는 spiders/spider_name.py를 생성해준다.
# -*- coding: utf-8 -*-
__author__ = 'loncle'
import scrapy
from scrapy.selector import Selector
import datetime
from selenium import webdriver
from crawling.items import CrawlingItem
import mysql.connector
class crawlingSpider(scrapy.Spider):
name = "crawler"
allowed_domains = ["bithumb.com"]
start_urls = ["https://www.bithumb.com/"] #, "https://www.bithumb.com/tradeview"]
def __init__(self):
self.browser = webdriver.Firefox()
def parse(self, response):
self.browser.get(response.url)
html = self.browser.find_element_by_xpath('//*').get_attribute('outerHTML')
self.browser.close()
selector = Selector(text=html)
for sel in selector.xpath('//table[@id="tableAsset"]/tbody/tr'):
item = CrawlingItem()
# 정적인 페이지 가져오기
item['coinName'] = sel.xpath('td[@class="click left_l"]/text()').extract()[0]
# 동적인 페이지 가져오기
item['coinPrice'] = sel.xpath('td[@class="right click padding_right50 line_td"]/strong/text()').extract()[1]
# 날짜
item['date'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M')
self.conn = mysql.connector.connect(
user = 'root',
password = 'qazaq123',
host = '127.0.0.1',
database = 'wordpress',
)
self.cursor = self.conn.cursor()
self.cursor.execute("INSERT INTO cc VALUES(\'%s\', \'%s\', \'%s\')" % (item['coinName'], item['coinPrice'], item['date']))
self.conn.commit()
self.cursor.close()
self.conn.close()
print("==================")
yield item
print("==================")
이렇게 소스를 만들어 주고, X window 환경으로 Crontab을 30분 간격으로 'scrapy crawl [crawler name]' 명령을 수행하도록 설정해놓으면, 30분마다 자동으로 DB에 코인의 가격들이 채워지는 것을 알 수 있다.
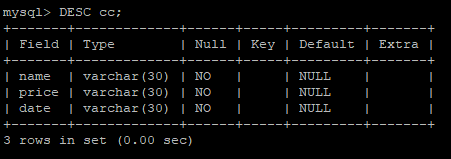
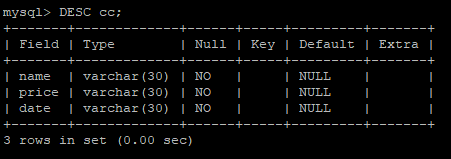 위는 DB에 가상화폐 정보를 넣기 위해 만든 table 구조이다.
위는 DB에 가상화폐 정보를 넣기 위해 만든 table 구조이다.
이제 크롤링을 할 차례다.
빗썸(Bithumb) 사이트에서 성공적으로 값을 크롤링해오는 것을 볼 수 있다.
크롤링하는 소스코드가 문제없이 작동했다면, DB에 정상적으로 값이 입력되는 것을 볼 수 있다.

이제 크롤링을 할 차례다.
크롤링하는 소스코드가 문제없이 작동했다면, DB에 정상적으로 값이 입력되는 것을 볼 수 있다.

2. Create a web page showing the graph of cryptocurrencies' price
이제 DB에 들어간 값들을 기반으로 그래프를 그릴 수 있게 페이지를 디자인하면 된다.
간단한 PHP지식이면 DB와 통신하는 것이 어렵지는 않을 것이다.
참고: https://opentutorials.org/course/1
↑↑↑ 위는 '생활코딩' 사이트이다. 웹을 다룰 때에는 '생활코딩'이 필수적이다.
소스코드:
https://github.com/seouk812/Cryptocurrencies-Chart-Based-on-Python-Web-Crawling
위 코드를 /var/www/html에 위치시키면 잘 작동한다.
대충 구조는, 메인 html 소스에서 원하는 가상화폐의 사진을 누르면, graph/ 에 위치한 DB 질의를 통해 얻은 가상화폐의 값을 그래프로 그려주는 php 소스를 띄워준다.
Summary
: Main HTML page -> [graph/1.php (bitcoin) or graph/2.php (ethereum) ...]
시연 영상
먼저, 크롤링이라는 단어가 생소했는데 무엇을 의미하는지 알게되었으며, 내가 직접 파이썬으로 크롤링을 수행한 후, 데이터들을 의미있게 사용했다는 것이 신기하고 재미있었다.
또한, 데이터들을 시각화하기 위해서 구글 차트(Google Chart)를 이용해봤는데, 웹이 다양한 기능을 할 수 있다는 것에 놀랐고, 웹에 대한 지식도 늘어난 것 같다.
이제 DB에 들어간 값들을 기반으로 그래프를 그릴 수 있게 페이지를 디자인하면 된다.
간단한 PHP지식이면 DB와 통신하는 것이 어렵지는 않을 것이다.
참고: https://opentutorials.org/course/1
↑↑↑ 위는 '생활코딩' 사이트이다. 웹을 다룰 때에는 '생활코딩'이 필수적이다.
소스코드:
https://github.com/seouk812/Cryptocurrencies-Chart-Based-on-Python-Web-Crawling
위 코드를 /var/www/html에 위치시키면 잘 작동한다.
대충 구조는, 메인 html 소스에서 원하는 가상화폐의 사진을 누르면, graph/ 에 위치한 DB 질의를 통해 얻은 가상화폐의 값을 그래프로 그려주는 php 소스를 띄워준다.
Summary
: Main HTML page -> [graph/1.php (bitcoin) or graph/2.php (ethereum) ...]
시연 영상
먼저, 크롤링이라는 단어가 생소했는데 무엇을 의미하는지 알게되었으며, 내가 직접 파이썬으로 크롤링을 수행한 후, 데이터들을 의미있게 사용했다는 것이 신기하고 재미있었다.
또한, 데이터들을 시각화하기 위해서 구글 차트(Google Chart)를 이용해봤는데, 웹이 다양한 기능을 할 수 있다는 것에 놀랐고, 웹에 대한 지식도 늘어난 것 같다.
댓글
댓글 쓰기